What Happens When You Hit a URL on a Browser?

If you want to share resources (mp3, mp4, pdf, HTML, etc.) from one device to another then you have to use networking!
In the networking world, there are two architectures we follow for that purpose:
- Client/Server: A device (or machine) will work as the server (that will serve resources) and another will work as a client (that will request resources). In this model, there will be one server but clients could be multiple.
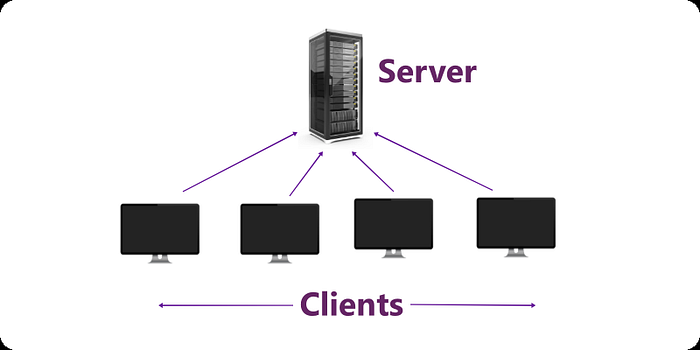
Fig: Client/Server Architecture
- Peer to Peer (P2P): Every device (or machine) will be a server as well as a client. So every machine can send and receive resources.
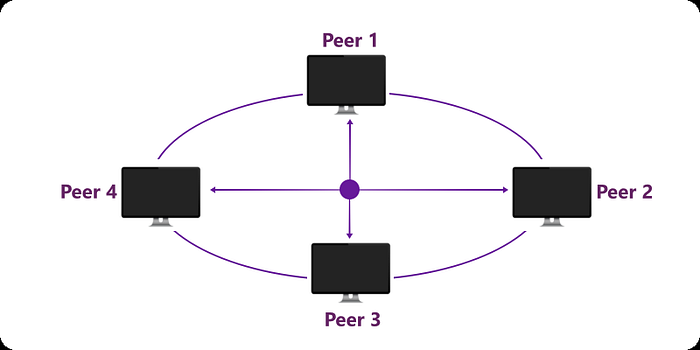
Fig: P2P Architecture
In our today’s discussion, we are interested in Client/Server architecture.
For this kind of networking architecture, HTTP(S) along with TCP/IP protocol are being used under the hood.
Let’s Understand Behind the Scene in an Easy Way
STEP 1: Client request — the user hits a URL (e.g.www.google.com) in the browser (i.e. client)
This means the client is requesting the resource for that URL.
But a server can not be requested using a domain URL, an IP address is required. So we need an IP for that particular domain.
STEP 2: DNS lookup
Firstly, the browser will try to find the IP from the browser's cache. If IP is not found then it will search on the OS cache. If still not found, then it will look up the DNS by the ISP e.g. Google DNS (8.8.8.8).
DNS: Stands for domain name system. It helps to convert the human readable domain name to its corresponding IP.
STEP 03: Establish connection — TCP/IP 3 ways handshaking
When the browser already knows the IP of the server a connection needs to be established between the client and the server.
TCP/IP uses 3 ways of handshaking to establish the connection.
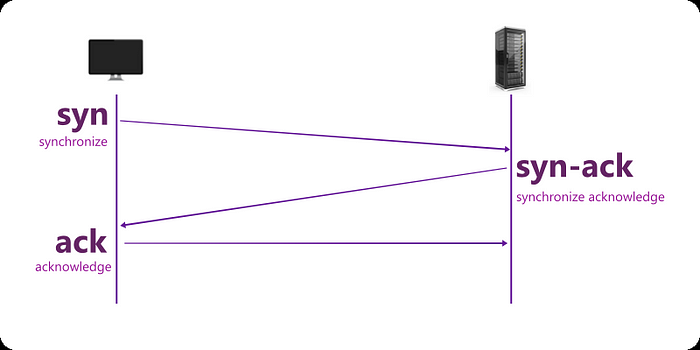
Fig: TCP/IP Handshaking: syn, syn-ack, ack
STEP 4: Communication
After establishing the connection, the client and the server can communicate with each other.

Fig: Behind the scene: while hitting a URL




